Как работает рейтинг в Google Поиске
Всем должно быть ясно, что утечка документации Google и общедоступные документы антимонопольных слушаний на самом деле не говорят нам, как именно работают рейтинги.
Структура результатов обычного поиска теперь настолько сложна (не в последнюю очередь из-за использования машинного обучения), что даже сотрудники Google, работающие над алгоритмами ранжирования, говорят, что больше не могут объяснить, почему количество совпадений равно одному или двум. Мы не знаем веса многих сигналов и точного взаимодействия.
Тем не менее, важно ознакомиться со структурой поисковой системы, чтобы понять, почему хорошо оптимизированные страницы не ранжируются или, наоборот, почему, казалось бы, короткие и неоптимизированные результаты иногда оказываются в верхней части рейтинга. Самый важный аспект заключается в том, что вам необходимо расширить свой взгляд на то, что действительно важно.
Вся доступная информация ясно это показывает. Любой, кто хотя бы незначительно участвует в ранжировании, должен включить эти выводы в свое мышление. Вы увидите свои веб-сайты с совершенно другой точки зрения и учтете дополнительные показатели в своем анализе, планировании и принятии решений.
Честно говоря, чрезвычайно сложно нарисовать действительно достоверную картину структуры системы. Информация в сети весьма разная по своей трактовке, а иногда и по терминологии, хотя имеется в виду одно и то же.
Пример: система, отвечающая за создание поисковой выдачи (страницы результатов поиска), которая оптимизирует использование пространства, называется Tangram. Однако в некоторых документах Google он также упоминается как Тетрис, что, вероятно, является отсылкой к известной игре.
За несколько недель кропотливой работы я много раз просматривал, анализировал, структурировал, отбрасывал и реструктуризировал почти 100 документов.
Эта статья не претендует на то, чтобы быть исчерпывающей или строго точной. Это отражает мои лучшие усилия (т. е. «насколько мне известно и убеждено») и немного исследовательского духа инспектора Коломбо. Результат — то, что вы видите здесь.
Новый документ, ожидающий посещения робота Googlebot
Когда вы публикуете новый веб-сайт, он не индексируется сразу. Google должен сначала узнать об URL-адресе. Обычно это происходит либо через обновленную карту сайта, либо через ссылку, размещенную там с уже известного URL-адреса.
Часто посещаемые страницы, такие как главная, естественным образом быстрее доводят информацию о ссылках до сведения Google.
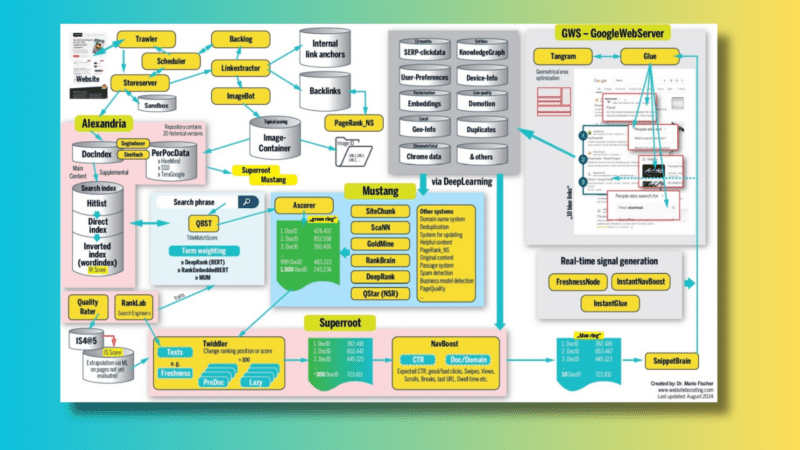
Система-траулер извлекает новый контент и отслеживает, когда следует повторно посетить URL-адрес для проверки обновлений. Этим управляет компонент, называемый планировщиком. Сервер магазина решает, пересылать ли URL-адрес или помещать его в песочницу.
Google отрицает существование этого ящика, но недавние утечки позволяют предположить, что там размещаются (предположительно) спам-сайты и малоценные сайты. Следует отметить, что Google, очевидно, пересылает часть спама, вероятно, для дальнейшего анализа с целью обучения своих алгоритмов.
Наш вымышленный документ преодолевает этот барьер. Исходящие ссылки из нашего документа извлекаются и сортируются по внутренним или внешним исходящим. Другие системы в основном используют эту информацию для анализа ссылок и расчета PageRank. (Подробнее об этом позже.)
Ссылки на изображения передаются ImageBot, который их вызывает, иногда со значительной задержкой, и помещают (вместе с идентичными или похожими изображениями) в контейнер изображений. Очевидно, что Trawler использует собственный PageRank для регулировки частоты сканирования. Если на веб-сайте больше трафика, частота сканирования увеличивается (ClientTrafficFraction).
Александрия: великая библиотека
Система индексирования Google под названием Alexandria присваивает уникальный DocID каждому фрагменту контента. Если контент уже известен, например, в случае дубликатов, новый идентификатор не создается; вместо этого URL-адрес связан с существующим DocID.
Важно! Google различает URL-адрес и документ. Документ может состоять из нескольких URL-адресов, содержащих схожий контент, включая версии на разных языках, если они правильно помечены. Здесь также сортируются URL-адреса с других доменов. Все сигналы от этих URL-адресов применяются через общий DocID.
Для дублированного контента Google выбирает каноническую версию, которая появляется в рейтингах поиска. Это также объясняет, почему другие URL-адреса иногда могут иметь аналогичный рейтинг; определение «исходного» (канонического) URL-адреса может со временем измениться.
Поскольку в сети существует только одна версия нашего документа, ей присвоен собственный DocID.
Отдельные сегменты нашего сайта ищутся по релевантным ключевым фразам и помещаются в поисковый индекс. Там «список совпадений» (все важные слова на странице) сначала отправляется в прямой индекс, который суммирует ключевые слова, встречающиеся несколько раз на странице.
Теперь происходит важный шаг. Отдельные ключевые фразы интегрируются в каталог слов инвертированного индекса (указатель слов). Там уже указано слово «карандаш» и все важные документы, содержащие это слово.
Проще говоря, поскольку в нашем документе несколько раз заметно встречается слово «карандаш», теперь оно указано в указателе слов с его DocID под записью «карандаш».
Идентификатору документа присваивается алгоритмически рассчитанный балл IR (поиск информации) для карандаша, который позже используется для включения в список сообщений. Например, в нашем документе слово «карандаш» выделено в тексте жирным шрифтом и содержится в H1 (хранится в AvrTermWeight). Такие и другие сигналы увеличивают показатель IR.
Google перемещает документы, считающиеся важными, в так называемый HiveMind, то есть в основную память. Google использует как быстрые твердотельные накопители, так и обычные жесткие диски (называемые TeraGoogle) для долгосрочного хранения информации, не требующей быстрого доступа. Документы и сигналы хранятся в основной памяти.
Примечательно, что, по оценкам экспертов, до недавнего бума искусственного интеллекта около половины мировых веб-серверов располагалось в Google. Обширная сеть взаимосвязанных кластеров позволяет миллионам модулей основной памяти работать вместе. Инженер Google однажды заметил на конференции, что теоретически в основной памяти Google может храниться вся сеть.
Интересно отметить, что ссылки, в том числе обратные, хранящиеся в HiveMind, имеют значительно больший вес. Например, ссылкам на важные документы придается гораздо большее значение, тогда как ссылки с URL-адресов в TeraGoogle (HDD) могут иметь меньший вес или вообще не учитываться.
Совет. Указывайте в своих документах правдоподобные и согласованные значения дат. BylineDate (дата в исходном коде), syntaticDate (извлеченная дата из URL-адреса и/или заголовка) и semanticDate (взятая из читаемого содержимого) используются, среди прочего.
Имитация актуальности путем изменения даты, безусловно, может привести к понижению рейтинга. Атрибут lastSignificantUpdate записывает, когда в документ было внесено последнее существенное изменение. Исправление мелких деталей или опечаток не влияет на этот счетчик.
Дополнительная информация и сигналы для каждого DocID динамически сохраняются в репозитории (PerDocData). Многие системы обращаются к этому вопросу позже, когда дело доходит до точной настройки релевантности. Полезно знать, что там хранятся последние 20 версий документа (через CrawlerChangerateURLHistory).
Google имеет возможность оценивать изменения с течением времени. Если вы хотите полностью изменить содержимое или тему документа, теоретически вам потребуется создать 20 промежуточных версий, чтобы переопределить старые сигналы содержимого. Вот почему восстановление домена с истекшим сроком действия (домена, который ранее был активен, но с тех пор был заброшен или продан, возможно, из-за неплатежеспособности) не дает никакого преимущества в рейтинге.
Если изменяется Admin-C домена и одновременно меняется его тематическое содержимое, машина легко распознает это на этом этапе. Затем Google обнуляет все сигналы, и предположительно ценный старый домен больше не дает никаких преимуществ перед совершенно новым зарегистрированным доменом.
QBST: кто-то ищет «карандаш»
Когда кто-то вводит слово «карандаш» в качестве поискового запроса в Google, QBST начинает свою работу. Поисковая фраза анализируется, и если она содержит несколько слов, соответствующие из них отправляются в индекс слов для поиска.
Процесс взвешивания терминов довольно сложен и включает в себя такие системы, как RankBrain, DeepRank (ранее BERT) и RankEmbeddedBERT. Соответствующие термины, такие как «карандаш», затем передаются в систему оценки для дальнейшей обработки.
Аскорер: «Зеленое кольцо» создано
Ascorer извлекает 1000 самых популярных DocID для слова «карандаш» из инвертированного индекса, ранжированного по показателю IR. Во внутренних документах этот список именуется «зеленым кольцом». В отрасли это известно как список сообщений.
The Ascorer является частью системы ранжирования, известной как Mustang, где дальнейшая фильтрация происходит с помощью таких методов, как дедупликация с использованием SimHash (тип отпечатка документа), анализ проходов, системы распознавания оригинального и полезного контента и т. д. Цель — уточнить 1000 кандидатов до «10 синих звеньев» или «синего кольца».
Наш документ о карандашах находится в списке публикаций, на данный момент он занимает 132-е место. Без дополнительных систем это была бы его окончательная позиция.
Суперкорень: превратите 1000 в 10!
За изменение рейтинга отвечает система Superroot, выполняющая точную работу по сокращению «зеленого кольца» (1000 DocID) до «синего кольца» всего с 10 результатами.
Эту задачу выполняют Twiddlers и NavBoost. Вероятно, здесь используются и другие системы, но их точные детали неясны из-за расплывчатой информации.
Google Caffeine больше не существует в этой форме. Только название осталось.
Сейчас Google работает с бесчисленным количеством микросервисов, которые взаимодействуют друг с другом и генерируют атрибуты документов, которые используются в качестве сигналов самыми разными системами ранжирования и переранжирования и с помощью которых нейронные сети обучаются делать прогнозы.
Фильтр после фильтра: Twiddlers
В различных документах указывается, что используется несколько сотен систем Twiddler. Думайте о Twiddler как о плагине, похожем на плагины WordPress.
Каждый Twiddler имеет свою собственную цель фильтра. Они созданы таким образом, потому что их относительно легко создать и они не требуют изменений в сложных алгоритмах ранжирования в Ascorer.
Изменение этих алгоритмов является сложной задачей и потребует тщательного планирования и программирования из-за потенциальных побочных эффектов. Напротив, твиддлеры действуют параллельно или последовательно и не знают о деятельности других твиддлеров.
Существует два типа твиддлеров.
PreDoc Twiddlers может работать со всем набором из нескольких сотен DocID, поскольку они практически не требуют дополнительной информации или вообще не требуют ее.
Напротив, твиддлерам типа «Ленивый» требуется больше информации, например, из базы данных PerDocData. Это занимает соответственно больше времени и является более сложным.
По этой причине PreDocs сначала сокращает список сообщений до значительно меньшего количества записей, а затем начинает с более медленных фильтров. Это экономит огромное количество вычислительных мощностей и времени.
Некоторые твиддлеры корректируют показатель IR в положительную или отрицательную сторону, в то время как другие напрямую изменяют позицию в рейтинге. Поскольку наш документ является новым для индекса, Twiddler, предназначенный для того, чтобы дать последним документам больше шансов на ранжирование, может, например, умножить оценку IR в 1,7 раза. Эта корректировка может переместить наш документ со 132-го места на 81-е.
Другой Twiddler увеличивает разнообразие (strideCategory) в результатах поиска, обесценивая документы со схожим содержанием. В результате несколько документов впереди нас теряют свои позиции, позволяя нашему карандашному документу подняться на 12 позиций до 69. Кроме того, Twiddler, который ограничивает количество страниц блога до трех для определенных запросов, повышает наш рейтинг до 61.
Наша страница получила ноль (значение «Да») для атрибута CommercialScore. Система Mustang во время анализа определила намерение продать. Google, вероятно, знает, что за поиском «карандаш» часто следуют уточненные запросы, такие как «купить карандаш», что указывает на коммерческое или транзакционное намерение. Twiddler, созданный с учетом этого намерения поиска, добавляет релевантные результаты и поднимает нашу страницу на 20 позиций, поднимая нас до 41.
В игру вступает еще один Twiddler, применяющий «штраф за третью страницу», который ограничивает страницы, подозреваемые в спаме, до максимального ранга 31 (стр. 3). Лучшая позиция документа определяется атрибутом BadURL-demoteindex, который предотвращает ранжирование выше этого порога. Для этой цели используются такие атрибуты, как DemoteForContent, DemoteForForwardlinks и DemoteForBacklinks. В результате три документа выше нас понижаются, что позволяет нашей странице подняться на позицию 38.
Наш документ мог бы быть обесценен, но для простоты мы предполагаем, что он остался неизменным. Давайте рассмотрим еще один Twiddler, который оценивает, насколько наша карандашная страница соответствует нашему домену на основе встраивания. Поскольку наш сайт посвящен исключительно пишущим инструментам, это работает нам на пользу и отрицательно влияет на 24 других документа.
Например, представьте себе сайт сравнения цен с разнообразной тематикой, но с одной «хорошей» страницей о карандашах. Поскольку тема этой страницы существенно отличается от общей направленности сайта, этот Twiddler будет обесценивать ее.
Такие атрибуты, как siteFocusScore и siteRadius, отражают это тематическое расстояние. В результате наш рейтинг IR снова повышается, а другие результаты понижаются, что поднимает нас на 14-е место.
Как уже упоминалось, Twiddlers служат широкому кругу целей. Разработчики могут экспериментировать с новыми фильтрами, множителями или конкретными ограничениями позиций. Можно даже поставить результат непосредственно перед другим результатом или после него.
Один из просочившихся внутренних документов Google предупреждает, что некоторые функции Twiddler должны использоваться только экспертами и после консультации с основной поисковой командой.
«Если вы думаете, что понимаете, как они работают, поверьте нам: это не так. Мы тоже не уверены, что это так».
– Утечка документа «Краткое руководство Twiddler – Superroot»
Существуют также Twiddlers, которые только создают аннотации и добавляют их в DocID на пути к поисковой выдаче. Затем во фрагменте появляется, например, изображение, или позже заголовок и/или описание динамически перезаписываются.
Если во время пандемии вы задавались вопросом, почему национальный орган здравоохранения вашей страны (например, Министерство здравоохранения и социальных служб США) постоянно занимает первое место в результатах поиска по COVID-19, то это произошло благодаря Twiddler, который увеличивает количество официальных ресурсов на основе язык и страну с помощью queriesForWhichOfficial.
У вас мало контроля над тем, как Twiddler меняет порядок ваших результатов, но понимание его механизмов может помочь вам лучше интерпретировать колебания рейтинга или «необъяснимые рейтинги». Полезно регулярно просматривать результаты поиска и отмечать типы результатов.
Например, вы постоянно видите только определенное количество сообщений на форуме или в блоге, даже с разными поисковыми фразами? Сколько результатов являются транзакционными, информационными или навигационными? Появляются ли одни и те же домены неоднократно или они меняются при небольших изменениях поисковой фразы?
Если вы заметили, что в результаты включены только несколько интернет-магазинов, возможно, будет менее эффективно пытаться ранжировать аналогичный сайт. Вместо этого рассмотрите возможность сосредоточиться на более информационно-ориентированном контенте. Однако не спешите с выводами, поскольку система NavBoost будет обсуждаться позже.
Оценщики качества Google и RankLab
Несколько тысяч специалистов по оценке качества работают в Google по всему миру, чтобы оценить определенные результаты поиска и протестировать новые алгоритмы и/или фильтры, прежде чем они выйдут в свет.
Google объясняет: «Их рейтинги не влияют напрямую на рейтинг».
По сути это верно, но эти голоса оказывают существенное косвенное влияние на рейтинг.
Вот как это работает: оценщики получают URL-адреса или поисковые фразы (результаты поиска) от системы и отвечают на заранее определенные вопросы, которые обычно задаются на мобильных устройствах.
Например, их могут спросить: «Понятно ли, кто и когда написал этот контент? Есть ли у автора профессиональный опыт по этой теме?» Ответы на эти вопросы сохраняются и используются для обучения алгоритмов машинного обучения. Эти алгоритмы анализируют характеристики хороших и заслуживающих доверия страниц в сравнении с менее надежными.
Этот подход означает, что вместо того, чтобы полагаться на членов поисковой группы Google для создания критериев ранжирования, алгоритмы используют глубокое обучение для выявления закономерностей на основе обучения, проведенного оценщиками-людьми.
Давайте рассмотрим мысленный эксперимент, чтобы проиллюстрировать это. Представьте, что люди интуитивно оценивают часть контента как заслуживающую доверия, если она включает в себя фотографию автора, полное имя и ссылку на биографию LinkedIn. Страницы, на которых отсутствуют эти функции, воспринимаются как менее заслуживающие доверия.
Если нейронная сеть обучена на различных функциях страницы наряду с оценками «Да» или «Нет», она определит эту характеристику как ключевой фактор. После нескольких положительных тестовых запусков, которые обычно длятся не менее 30 дней, сеть может начать использовать эту функцию в качестве сигнала ранжирования. В результате страницы с изображением автора, полным именем и ссылкой на LinkedIn могут получить повышение рейтинга (возможно, с помощью Twiddler), а страницы без этих функций могут быть обесценены.
Официальная позиция Google, заключающаяся в том, что мы не обращаем внимания на авторов, может соответствовать этому сценарию. Однако утечка информации раскрывает такие атрибуты, как isAuthor, и такие понятия, как «снятие отпечатков пальцев автора» через атрибут AuthorVectors, который делает идиолект (индивидуальное использование терминов и формулировок) автора различимым или идентифицируемым – опять же через вложения.
Оценки рейтеров объединяются в показатель «информационной удовлетворенности» (IS). Хотя многие оценщики вносят свой вклад, оценка IS доступна только для небольшой части URL-адресов. Для других страниц с похожими шаблонами этот показатель экстраполируется для целей ранжирования.
Google отмечает: «Многие документы не требуют кликов, но могут быть важными». Если экстраполяция невозможна, система автоматически отправляет документ оценщикам для выставления оценки.
Термин «золотой» упоминается в отношении оценщиков качества, что позволяет предположить, что для определенных документов или типов документов может существовать золотой стандарт. Можно сделать вывод, что соответствие ожиданиям тестировщиков может помочь вашему документу соответствовать этому золотому стандарту. Кроме того, вполне вероятно, что один или несколько Twiddlers могут значительно повысить количество DocID, считающихся «золотыми», и потенциально вывести их в десятку лучших.
Оценщики качества обычно не являются штатными сотрудниками Google и могут работать через сторонние компании. Напротив, собственные эксперты Google работают в RankLab, где они проводят эксперименты, разрабатывают новые Twiddlers и оценивают, улучшают ли эти или усовершенствованные Twiddlers качество результатов или просто фильтруют спам.
Проверенные и эффективные Twiddlers затем интегрируются в систему Mustang, где используются сложные, вычислительно интенсивные и взаимосвязанные алгоритмы.
Анонсы наших новых статей в Телеграме