ИИ в SEO: как решать юридические проблемы и обеспечивать соблюдение требований
Искусственный интеллект (ИИ) может стать жизненно важным инструментом для брендов, стремящихся расширить свое присутствие в Интернете.
Однако интеграция искусственного интеллекта в маркетинговые стратегии неизбежно порождает юридические вопросы и новые правила, которые агентствам должны тщательно соблюдать.
В этой статье вы узнаете:
Как предприятия, SEO и медиа-агентства могут минимизировать юридические риски при реализации стратегий, улучшенных искусственным интеллектом.
Полезные инструменты для уменьшения предвзятости ИИ и удобный процесс проверки качества контента, созданного ИИ.
Как агентства могут решать основные проблемы внедрения ИИ, чтобы обеспечить эффективность и соблюдение требований для своих клиентов.
Соображения по соблюдению законодательства
Интеллектуальная собственность и авторские права
Важнейшей юридической проблемой при использовании ИИ в SEO и средствах массовой информации является соблюдение законов об интеллектуальной собственности и авторских правах.
Системы искусственного интеллекта часто собирают и анализируют огромные объемы данных, включая материалы, защищенные авторским правом.
Против OpenAI уже подано несколько исков за нарушение авторских прав и конфиденциальности.
Компании предъявлены иски по обвинению в несанкционированном использовании книг, защищенных авторским правом, для обучения ChatGPT и незаконном сборе личной информации от пользователей Интернета с использованием их моделей машинного обучения.
Из-за проблем конфиденциальности, связанных с обработкой и сохранением пользовательских данных OpenAI, в конце марта Италия полностью заблокировала использование ChatGPT.
Запрет снят после того, как компания внесла изменения, направленные на повышение прозрачности обработки пользовательских данных чат-ботом и добавление возможности отказаться от разговоров ChatGPT, используемых для обучения алгоритмов.
Однако с запуском GPTBot, сканера OpenAI, могут возникнуть дополнительные юридические вопросы.
Чтобы избежать потенциальных юридических проблем и претензий о нарушении прав, агентства должны обеспечить обучение всех моделей ИИ на авторизованных источниках данных и соблюдать ограничения авторских прав:
Убедитесь, что данные были получены законным путем и агентство имеет соответствующие права на их использование.
Отфильтровывайте данные, которые не имеют необходимых юридических разрешений или имеют низкое качество.
Проводите регулярные проверки данных и моделей искусственного интеллекта, чтобы убедиться, что они соответствуют правам и законам об использовании данных.
Проведите юридическую консультацию по вопросам прав на данные и конфиденциальности, чтобы убедиться, что ничто не противоречит юридической политике.
Прежде чем модели искусственного интеллекта можно будет интегрировать в рабочие процессы и проекты, скорее всего, в вышеупомянутых обсуждениях потребуется участие как юристов агентства, так и клиента.
Конфиденциальность и защита данных
Технологии искусственного интеллекта в значительной степени полагаются на данные, которые могут включать конфиденциальную личную информацию.
Сбор, хранение и обработка пользовательских данных должны осуществляться в соответствии с соответствующими законами о конфиденциальности, такими как Общий регламент по защите данных (GDPR) в Европейском Союзе.
Более того, недавно принятый Закон ЕС об искусственном интеллекте также уделяет особое внимание решению проблем конфиденциальности данных, связанных с системами искусственного интеллекта.
Это не лишено смысла. Крупные корпорации, такие как Samsung, полностью запретили ИИ из-за раскрытия конфиденциальных данных, загруженных в ChatGPT.
Поэтому, если агентства используют данные клиентов в сочетании с технологией искусственного интеллекта, им следует:
Отдавайте приоритет прозрачности при сборе данных.
Получите согласие пользователя.
Внедрите надежные меры безопасности для защиты конфиденциальной информации.
В таких случаях агентства могут уделять приоритетное внимание прозрачности сбора данных, четко сообщая пользователям, какие данные будут собираться, как они будут использоваться и кто будет иметь к ним доступ.
Чтобы получить согласие пользователя, убедитесь, что согласие предоставляется осознанно и свободно с помощью четких и простых для понимания форм согласия, в которых объясняются цель и преимущества сбора данных.
Кроме того, к надежным мерам безопасности относятся:
Шифрование данных.
Контроль доступа.
Анонимизация данных (где это возможно).
Регулярные проверки и обновления.
Например, политика OpenAI соответствует необходимости обеспечения конфиденциальности и защиты данных и сосредоточена на обеспечении прозрачности, согласия пользователей и безопасности данных в приложениях ИИ.
Справедливость и предвзятость
Алгоритмы искусственного интеллекта, используемые в SEO и средствах массовой информации, могут непреднамеренно закреплять предвзятость или дискриминацию в отношении определенных лиц или групп.
Агентства должны проявлять инициативу в выявлении и смягчении алгоритмической предвзятости. Это особенно важно в соответствии с новым Законом ЕС об искусственном интеллекте, который запрещает системам искусственного интеллекта несправедливо влиять на поведение людей или проявлять дискриминационное поведение.
Чтобы снизить этот риск, агентствам следует обеспечить включение разнообразных данных и точек зрения в разработку моделей ИИ и постоянно отслеживать результаты на предмет потенциальной предвзятости и дискриминации.
Этого можно добиться с помощью инструментов, помогающих уменьшить предвзятость, таких как AI Fairness 360, IBM Watson Studio и Google What-If Tool.
Ложное или вводящее в заблуждение содержание
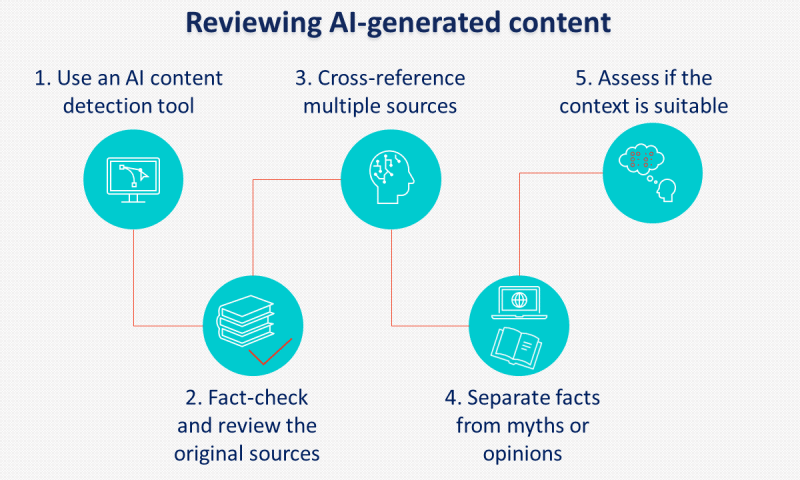
Инструменты искусственного интеллекта, в том числе ChatGPT, могут генерировать синтетический контент, который может быть неточным, вводящим в заблуждение или поддельным.
Например, искусственный интеллект часто создает фейковые онлайн-обзоры для продвижения определенных мест или продуктов. Это может привести к негативным последствиям для компаний, которые полагаются на контент, создаваемый искусственным интеллектом.
Внедрение четких политик и процедур проверки контента, созданного искусственным интеллектом, перед публикацией имеет решающее значение для предотвращения этого риска.
Еще одна практика, которую следует учитывать, — это маркировка контента, созданного искусственным интеллектом. Хотя Google, похоже, не соблюдает это требование, многие политики поддерживают маркировку ИИ.
Ответственность и подотчетность
Поскольку системы искусственного интеллекта становятся более сложными, возникают вопросы ответственности.
Агентства, использующие ИИ, должны быть готовы взять на себя ответственность за любые непредвиденные последствия, возникающие в результате его использования, в том числе:
Предвзятость и дискриминация при использовании ИИ для сортировки кандидатов при приеме на работу.
Возможность злоупотребления возможностями ИИ в злонамеренных целях, таких как кибератаки.
Потеря конфиденциальности, если информация собирается без согласия.
Закон ЕС об искусственном интеллекте вводит новые положения о системах искусственного интеллекта высокого риска, которые могут существенно повлиять на права пользователей, подчеркивая, почему агентства и клиенты должны соблюдать соответствующие условия и политики при использовании технологий искусственного интеллекта.
Некоторые из наиболее важных условий и политик OpenAI касаются контента, предоставляемого пользователем, точности ответов и обработки персональных данных.
Политика контента гласит, что OpenAI присваивает пользователю права на созданный контент. В нем также указано, что созданный контент можно использовать для любых целей, в том числе коммерческих, при условии соблюдения законодательных ограничений.
Однако в нем также говорится, что выходные данные не могут быть ни полностью уникальными, ни точными, а это означает, что контент, созданный с помощью ИИ, всегда должен тщательно проверяться перед использованием.
Что касается личных данных, OpenAI собирает всю информацию, вводимую пользователями, включая загружаемые файлы.
При использовании сервиса для обработки персональных данных пользователи должны предоставить юридически адекватные уведомления о конфиденциальности и заполнить форму запроса на обработку данных.
Агентства должны активно решать вопросы подотчетности, отслеживать результаты работы ИИ и внедрять надежные меры контроля качества, чтобы смягчить потенциальную юридическую ответственность.
Анонсы наших новых статей в Телеграме