Оптимизация LLM: можете ли вы повлиять на результаты генеративного ИИ?
С момента появления генеративного искусственного интеллекта большие языковые модели (LLM) завоевали мир и нашли свое применение в поисковых системах.
Но можно ли активно влиять на производительность ИИ с помощью оптимизации больших языковых моделей (LLMO) или генеративной оптимизации ИИ (GAIO)?
В этой статье обсуждаются развивающиеся аспекты SEO и неопределенное будущее оптимизации LLM в поисковых системах на основе искусственного интеллекта, а также мнения экспертов по науке о данных.
Что такое оптимизация LLM или генеративная оптимизация ИИ (GAIO)?
Цель GAIO – помочь компаниям позиционировать свои бренды и продукты в результатах ведущих программ LLM, таких как GPT и Google Bard, которые известны тем, что эти модели могут повлиять на многие будущие решения о покупке.
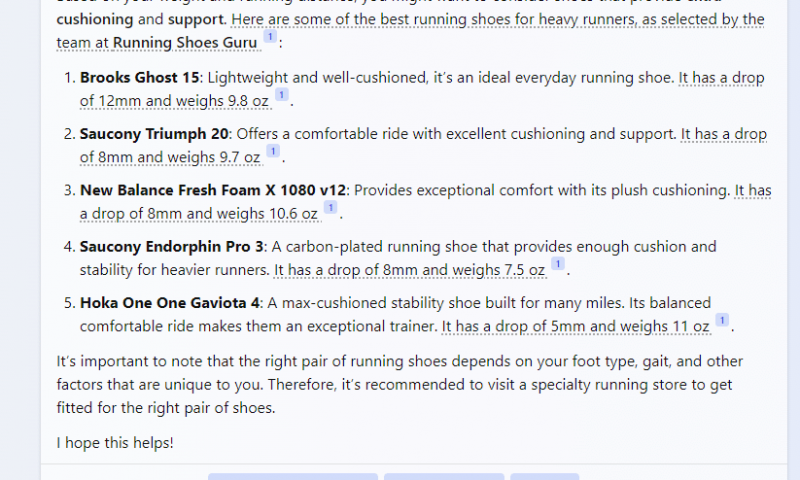
Например, если вы ищете в чате Bing лучшие кроссовки для бегуна весом 96 килограммов, пробегающего 20 километров в неделю, вам будут предложены кроссовки Brooks, Saucony, Hoka и New Balance.
Когда вы спрашиваете в Bing Chat о безопасных, удобных для всей семьи автомобилях, достаточно больших для покупок и путешествий, он предлагает модели Kia, Toyota, Hyundai и Chevrolet.
Подход потенциальных методов, таких как оптимизация LLM, заключается в том, чтобы отдавать предпочтение определенным брендам и продуктам при решении соответствующих вопросов, ориентированных на транзакции.
Как составляются эти рекомендации?
Предложения от Bing Chat и других инструментов генеративного искусственного интеллекта всегда контекстуальны. В качестве источника рекомендаций ИИ в основном использует нейтральные вторичные источники, такие как отраслевые журналы, новостные сайты, веб-сайты ассоциаций и государственных учреждений, а также блоги.
Результаты генеративного ИИ основаны на определении статистических частот. Чем чаще слова встречаются последовательно в исходных данных, тем больше вероятность того, что искомое слово окажется правильным в выходных данных.
Слова, часто упоминаемые в обучающих данных, статистически более похожи или семантически более близки.
Какие бренды и продукты упоминаются в определенном контексте, можно объяснить тем, как работают LLM.
LLM в действии
Современные LLM на основе преобразователей, такие как GPT или Bard, основаны на статистическом анализе совместного появления токенов или слов.
Для этого тексты и данные разбиваются на токены для машинной обработки и размещаются в семантических пространствах с помощью векторов. Векторами также могут быть целые слова (Word2Vec), сущности (Node2Vec) и атрибуты.
В семантике семантическое пространство также описывается как онтология. Поскольку LLM больше полагаются на статистику, чем на семантику, они не являются онтологиями. Однако благодаря объему данных ИИ приближается к семантическому пониманию.
Семантическая близость может быть определена с помощью евклидова расстояния или меры косинусного угла в семантическом пространстве.
Если объект часто упоминается в связи с некоторыми другими объектами или свойствами в обучающих данных, существует высокая статистическая вероятность семантической связи.
Метод этой обработки называется обработкой естественного языка на основе преобразователя.
НЛП описывает процесс преобразования естественного языка в форму, понятную машине, которая позволяет общаться между людьми и машинами.
НЛП включает в себя понимание естественного языка (NLU) и генерацию естественного языка (NLG).
При обучении LLM основное внимание уделяется NLU, а при выводе результатов, сгенерированных искусственным интеллектом, основное внимание уделяется NLG.
Идентификация сущностей посредством извлечения именованных сущностей играет особую роль в семантическом понимании и значении сущности в тематической онтологии.
Из-за частого совместного появления тех или иных слов эти векторы сближаются в семантическом пространстве: увеличивается семантическая близость и увеличивается вероятность принадлежности.
Результаты выводятся через NLG в соответствии со статистической вероятностью.
Например, предположим, что Chevrolet Suburban часто упоминается в контексте семьи и безопасности.
В этом случае LLM может связать этот объект с определенными атрибутами, такими как безопасный или семейный. Существует высокая статистическая вероятность того, что данная модель автомобиля связана с этими атрибутами.
Анонсы наших новых статей в Телеграме